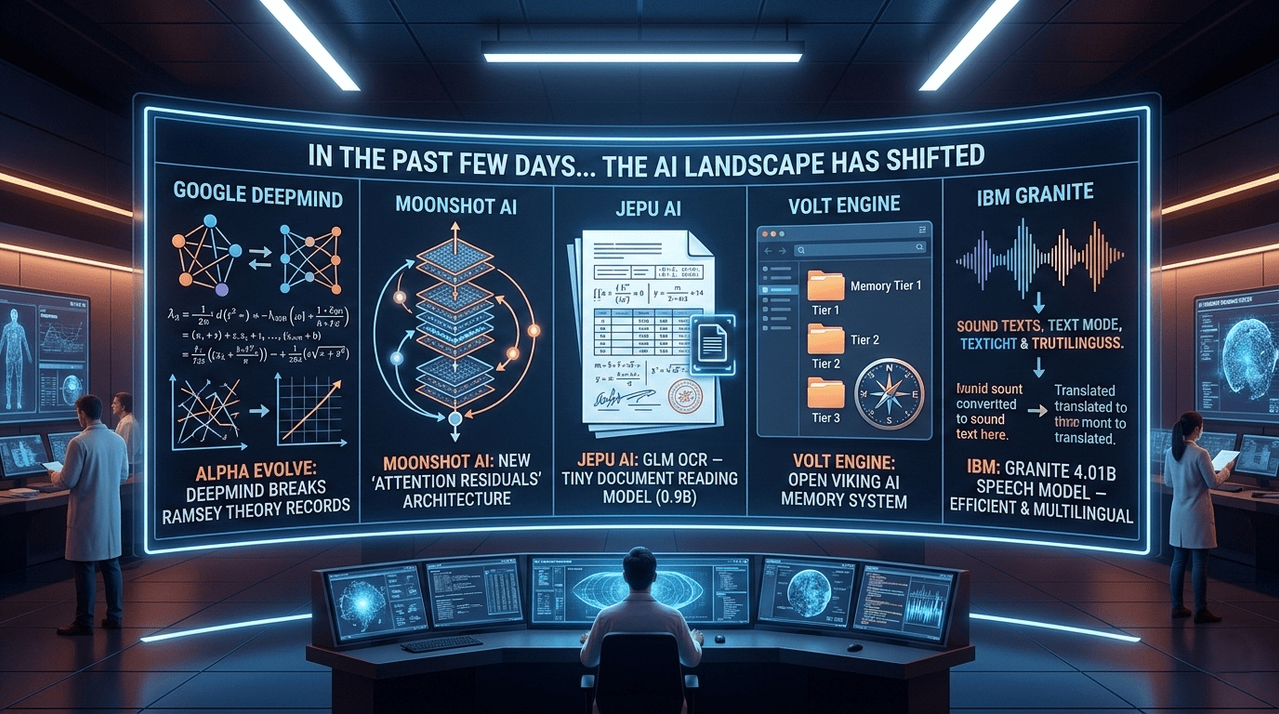
5 Recent Breakthroughs Shaking the AI Landscape
This past week has seen a whirlwind of activity in the AI sector, ranging from breakthroughs in theoretical mathematics to architectural overhauls that make models more efficient. From Google DeepMind’s record-breaking Alpha Evolve to IBM’s compact new speech model, the landscape is shifting rapidly.
Here is a breakdown of the five major developments you need to know about.
1. Alpha Evolve: Breaking Decades-Old Math Records
Google DeepMind has introduced Alpha Evolve, an AI system that recently shattered records in Ramsey theory—a branch of mathematics so notoriously difficult that legendary mathematician Paul Erdos once joked humanity should surrender to aliens rather than try to calculate certain Ramsey numbers.
Ramsey theory explores the point at which order becomes unavoidable within a network. For example, in any group of six people, you are guaranteed to find either three people who know each other or three who are total strangers. As these networks grow, the math becomes exponentially harder.
How it Works:
Instead of searching for the math solutions directly, Alpha Evolve searches for the algorithms that find the answers.
- LLM-Driven Evolution: Using Google’s Gemini model, the system starts with simple algorithms and iteratively modifies their code.
- Survival of the Fittest: Each new version is tested; if it performs better, it "survives" to be refined further.
- Discovery: The AI independently rediscovered several techniques previously developed by human mathematicians, proving it was learning genuine mathematical strategies.
The Result: Alpha Evolve pushed forward the lower bounds of five famous Ramsey numbers at once, breaking one record that had stood for 20 years.
2. Moonshot AI: Reimagining the Transformer
Researchers at Moonshot AI are questioning the fundamental architecture of modern AI. They introduced Attention Residuals, a concept aimed at fixing the "dilution" problem in deep neural networks.
In standard models, every layer's output is mixed with equal weight. As models get deeper, earlier information gets lost in the noise. Moonshot’s solution is to allow each layer to use attention to decide which previous layers actually matter.
- Efficiency: Models using Attention Residuals matched the performance of standard models while requiring 25% less computing power.
- Scalability: The architecture was tested on "Kimi Linear," a 48-billion parameter model, showing significant gains in reasoning, coding, and general knowledge.
3. GLM OCR: The Tiny Model for Big Documents
While many companies are building larger models, Jepu AI (in collaboration with Tsinghua University) released GLM OCR, a document-reading model that is remarkably small at just 0.9 billion parameters.
Despite its size, it excels where traditional OCR (Optical Character Recognition) fails:
- Complex Layouts: It accurately reads tables, formulas, stamps, and messy structured fields.
- Region-Based Processing: Instead of reading a whole page at once, it identifies specific sections (like a diagram or a paragraph) and processes them individually.
- Speed: It is roughly 50% faster than traditional approaches and can output structured data like JSON or Markdown directly, making it ideal for processing invoices and reports.
4. Open Viking: A "File System" for AI Memory
One of the biggest hurdles for AI agents is managing long-term memory. Volt Engine has released Open Viking, an open-source system that organizes AI memory like a computer file system rather than a messy pile of text fragments.
Key Features:
- Tiered Context Loading: Every piece of information is stored in three versions: a one-sentence summary, a medium overview, and the full text. The AI only opens the full file if the summary is relevant, saving massive amounts of "tokens" (processing power).
- Navigable Directories: Agents can browse folders and directories using commands similar to a computer terminal.
- Improved Accuracy: In tests involving long conversations, Open Viking boosted task completion rates from 35% to over 52%.
5. IBM Granite 4.01B: Efficiency in Speech
IBM continues its focus on enterprise-ready, efficient AI with Granite 4.01B Speech. This model is designed to be compact yet powerful, supporting English, French, German, Spanish, Portuguese, and Japanese.
- Modular Design: The system works in two steps—converting speech to text, then using a language model to process that text. This makes it much easier for developers to plug into existing apps.
- Open Source: Released under the Apache 2.0 license, it allows companies to use the model without the heavy commercial restrictions often found in proprietary systems.
- Performance: It achieved a strong 5.52% Word Error Rate on the Open ASR (Automatic Speech Recognition) leaderboard.
The speed of these developments—from mathematical breakthroughs to more efficient memory systems—suggests that the next generation of AI will be characterized not just by size, but by smarter architecture and better logic.




Comments
No comments yet. Be the first to share your thoughts!
Leave a Comment